先日はISUCON14に参加しましたが*1 、その直前まで素振りがてら catatsuy/private-isu をPHP で解いていました。普段ISUCONはGo言語で参加していますが、他言語での挑戦にも興味がでてきたため、PHP でやってみることにしました。
実際のコードと作業ログは以下のリポジトリ にまとめてありますので、これから試してみたいという方の参考になればとても嬉しいです。
前提
private-isu の執筆時点のREADMEに記載されている「推奨インスタンス タイプ」のインスタンス を競技用とベンチマーカー用で1台ずつ建てています ( c7a.large と c7a.xlarge )。
github.com
以前Go実装で挑戦したことがありますが、この時のインスタンス タイプは c6i.large と c6i.xlarge だったようなので、点数について単純比較はできなさそうです。
blog.stenyan.jp
デプロイ
今回は rsync で webapp/php ディレクト リを丸ごとデプロイするという方式を取りました*2 。
GitHub にあげているコードは .gitignore に vendor 含めているので、GitHub からpullしてアプリケーションを動かしたい場合は毎回 composer install が必要になります。 rsync でデプロイする場合は手元の環境で既に composer install が済んでいればあとは丸ごとデプロイするだけなのが今回の利点でした。
Makefile に以下のコードを記載することで、 make deploy-app を実行するだけでアプリケーションをデプロイできるようにしました。
deploy-app:
rsync -av webapp/php/ isu01:~/private_isu/webapp/php/
プロファイリング
今回は tkuchiki/alp と pt-query-digest で遅いエンドポイントや遅いクエリを分析しました。
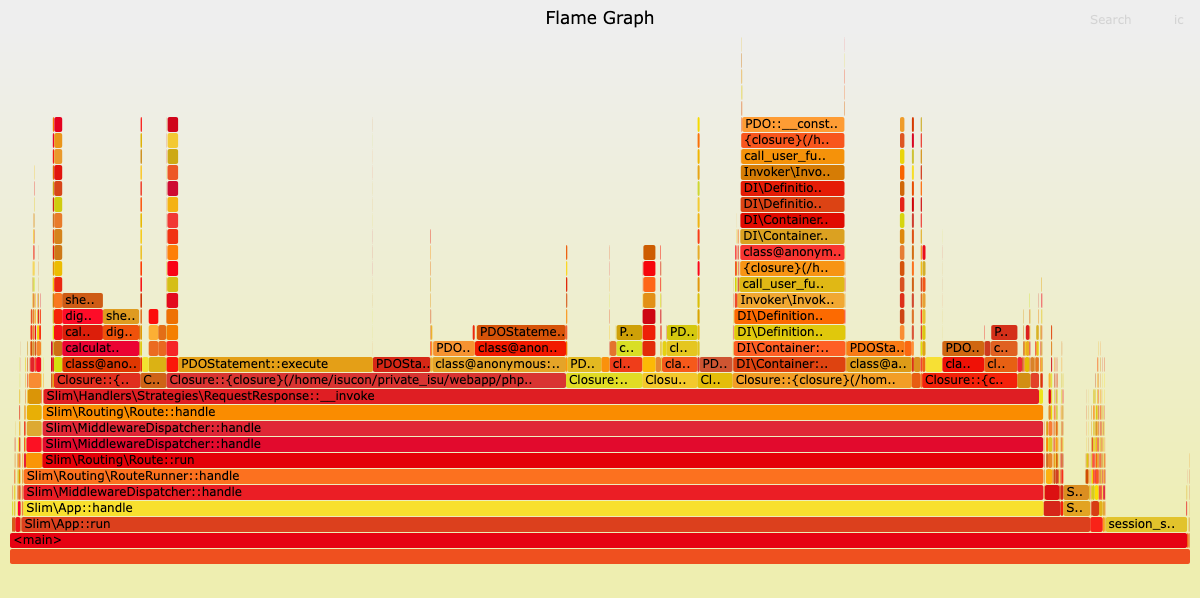
その上でアプリケーションのボトルネック をさらに分析するために、Go言語でISUCONに挑戦する際に活用してきた pprof による Flamegraph を利用したアプリケーションの負荷の可視化と同じようなものが使いたくなり、調査しました。
参考にした資料一覧:
はじめは xhprof を使う方式を検討して少し試していましたが、最終的に Reli を使うことにしました。
Reliの利点はアプリケーションコードに手を入れずに使えることです。Go言語のpprofを使う場合は毎回アプリケーションコードに手を入れていたことを考えると、Reliはあまりにも便利で驚きました。おすすめします。
private-isu で Reli を使う
簡単に private-isu で Reli を使って FlameGraph を出力する方法を紹介します。
まずはインスタンス にReliを入れます。
composer create-project reliforp/reli-prof
cd reli-prof
動いているプロセスの名前を確認しておきます。
$ ps auxfw | grep fpm
root 594 0 .0 0 .6 209068 23900 ? Ss 11:31 0:00 php-fpm: master process ( /etc/php/ 8 . 3 /fpm/php-fpm.conf )
isucon 2071 0 .1 0 .4 209632 19228 ? S 11:49 0:00 \_ php-fpm: pool www
isucon 2150 0 .0 0 .4 209632 19332 ? S 11:49 0:00 \_ php-fpm: pool www
isucon 2181 0 .0 0 .4 209632 18792 ? S 11:50 0:00 \_ php-fpm: pool www
isucon 2214 0 .0 0 .0 7076 2176 pts/0 S+ 11:51 0:00 \_ grep fpm
i:daemon というサブコマンドを利用して、ベンチ実行中にトレースを取得します。結果をファイルに保存しておきます。
sudo ./reli i:daemon -P " php-fpm " > traces.log
ベンチマーク の実行が終わったら c:flamegraph サブコマンドを利用してFlameGraph形式の結果をsvg ファイルに書き出します。
./reli c:flamegraph < traces.log > traces.svg
最後にローカル環境にsvg ファイルをダウンロードしてブラウザで開いてみると、FlameGraphが表示されます。
rsync isu01:~/reli-prof/traces.svg ./
FlameGraphの様子
設定ファイルの確認・アプリケーションエラーログの出力
private-isu のマニュアルでは nginx と php8.3-fpm.service のログを確認することが案内されています。
php -fpmの設定については、/etc/php /8.3/fpm/以下にあります。
エラーなどの出力については、
$ sudo journalctl -f -u php8.3-fpm
などで見ることができます。
private-isu/manual.md at 6de65501fa86f0cca01ac70ac3be18ce65703bd3 · catatsuy/private-isu · GitHub
実際触っていると php8.3-fpm.service をみていても正直ほしい情報はそんなに流れてこなくて、基本 nginx のエラーログをみて判断する感じになります。
php.ini にエラーログの設定を追加することによって、アプリケーションのエラーログを書き出すことができるようになります。php.ini の場所はアプリケーション中(例えばトップページを表示するロジックの中で) phpinfo(); を一時的に追加しブラウザから確認しました。
private-isuの場合、PHP 8.3 向けの FPM の設定ファイルは /etc/php/8.3/fpm/php.ini にありました。設定ファイル内に error_log がコメントアウト されていました。デフォルトではエラーログの出力先は空なので、お好きなパスを指定してあげます。
; Log errors to specified file. PHP's default behavior is to leave this value
; empty.
; https://php.net/error-log
; Example:
- ;error_log = php_errors.log
+ error_log = /var/log/php_errors.log
ファイルを一応作っておきます。
sudo touch /var/log/php_errors.log
sudo chmod 664 /var/log/php_errors.log
sudo chown isucon:isucon /var/log/php_errors.log
systemctlの再起動をして反映します。
sudo systemctl daemon-reload
sudo systemctl restart php8.3-fpm.service
これでエラーが起きた際に指定したファイルにアプリケーションのログが出力されるようになります。
sudo tail -f /var/log/php_errors.log
PDO::ATTR_PERSISTENT や composer autoloader optimize の設定PHP (PDO) でデータベースの接続をプールして使い回すには PDO::ATTR_PERSISTENT を設定する必要があります。
return new PDO(
"mysql:dbname={$config['db']['database']};host={$config['db']['host']};port={$config['db']['port']};charset=utf8mb4",
$config['db']['username'],
- $config['db']['password']
+ $config['db']['password'],
+ array(PDO::ATTR_PERSISTENT => true)
);
また、 composer の autoloader に対しても最適化をするための設定があるようです。 以下のように "optimize-autoloader": true, を composer.json に追加しておくと良いでしょう。
{
+ "optimize-autoloader": true,
"require": {
"slim/slim": "^4.7",
...
}
}
composerのサイトを見に行くとトレードオフ は基本的になく、本番環境では有効化しておくことをおすすめされているのでISUCONでもとりあえずやっておくのは良いと思います。
There are no real trade-offs with this method. It should always be enabled in production.
Autoloader optimization - Composer
PHP 8.0 からはJIT コンパイラ を有効化することでパフォーマンス向上を見込めます。
phpinfo() の出力結果をみると、 JIT の設定は opcache の中にあるようで、 opcache は別途設定ファイルがあるようです。
PHP 8.3の場合は /etc/php/8.3/mods-available/opcache.ini に設定ファイルがあったので、以下のような設定を追加しJIT を有効化しました。
; configuration for php opcache module
; priority=10
zend_extension=opcache.so
+ opcache.enable_cli=1
+ opcache.jit=on
+ opcache.jit_buffer_size=100M
詳しくはこちら:
www.php.net
PHP 8.4へのバージョンアップPHP -FPMを扱ったままPHP のバージョンをアップグレードすることもできました。
参考: PHP 8.4 Installation and Upgrade guide for Ubuntu and Debian • PHP.Watch
バージョンの上げ方としては、各種パッケージをインストールし、
sudo LC_ALL =C.UTF-8 add-apt-repository ppa:ondrej/php
sudo apt update
sudo apt install php8.4-cli php8.4-fpm php8.4-mysql
php8.3-fpm を停止、 php8.4-fpm を有効化する、
sudo systemctl stop php8.3-fpm.service
sudo systemctl disable php8.3-fpm.service
sudo systemctl start php8.4-fpm.service
sudo systemctl enable php8.4-fpm.service
FPMのプールの設定が /etc/php/8.3/fpm/pool.d/www.conf にあったので 8.3 と 8.4 の差分を確認して揃えます。
- user = www-data
- group = www-data
+ user = isucon
+ group = isucon
...
- listen = /run/php/php8.4-fpm.sock
+ listen = 127.0.0.1:9000
再起動します。
sudo systemctl restart php8.4-fpm.service
sudo systemctl restart nginx.service
nginxの設定がlocalhost の9000番に向いているままであれば設定をいじらなくてもそのままPHP 8.4の状態でつながります。
Unix domain socket を使うように変更したい場合はこの www.conf の設定と nginx の設定を合わせて変更する必要がありました。
github.com
PHP -FPMを捨ててRoadRunnerへ (移行失敗)徐々にPHP -FPMがボトルネック になっていることに気づき、以下のスライドを参考にRoadRunnerへの移行を試みました。
結論としては結構大変で諦めてしまいました。その代わり、RoadRunnerへ移行するために必要な手順を理解することができました。
RoadRunnerの設定ファイル (rr.yaml) の追加
RoadRunner向けworkerファイルの追加 (worker.php)
workerファイルから既存のDI ContainerやRoutesの設定をハンドリングできるようにコードを調整
Ubuntu 上にRoadRunnerをインストールし、systemd向けのユニットファイルを定義 (デーモン化)PHP -FPMデーモンの停止・無効化。RoadRunnerの起動・有効化nginxの設定で既存のFastCGI からRoadRunnerの設定を参照するように変更
ブラウザ上で "なんとなくprivate-isuが動く" 状態にできましたが、よくよく見てみると画像アップロード周りで壊れていたり、複数workerに対応できなかったりしてベンチマーカーがエラーを返してしまいました。以下のPull Requestが試していた様子となります。
点数遷移
細かいFlameGraphの様子などは以下のドキュメントにまとめていますが、ここでもざっとやった改善と点数の推移を記載します。
github.com
以下みていくと、ISUCON本*3 でも紹介されている改善を愚直にやると点数がどんどんあがっていって、PHP っぽい改善で効果を感じたのは「PDO::ATTR_PERSISTENTの設定」くらいでした。PHP バージョンアップやJIT 有効化を実施してみたものの、他の部分がボトルネック になっていたのであまり効果は感じられなかったのかもしれません(RoadRunner移行が達成できれば更なる点数の上昇は期待できたと思います)。
実施内容
点数
初回ベンチマーク (Ruby 実装)
1026
PHP 実装に切り替え3288
各種計測ログや計測を仕込んだ後
2802
commentsテーブルへindex追加
27353
ユーザの画像をnginxから配信
57835
トップページから呼んでいるクエリの全件取得をやめる + ORDER BY狙いINDEX追加
93054
他のmake_posts周辺クエリも同様に改善する
112481
make_posts内のpostのuserを引いてくるクエリをなくす
124309
make_posts内のcomment_countのN+1改善
141431
MySQL のbinlog無効化153314
make_posts内のcommentsのN+1解消
188721
make_posts内の最後のN+1解消
226115
外部コマンド呼び出しをやめる
257402
comments.user_id へのINDEX追加
272468
INDEXの追加とFORCE INDEXの指定
326587
MySQL の設定チューニング320129
静的ファイルをnginxから配信
323388
nginxのworker_connections増やしたりgzip の設定を追加したり
322611
ベンチマーカーインスタンス のファイルディスクリプタ を増やす
327821
opcache.jit 有効化
329357
PHP 8.4 へバージョンアップ (&& reliプロファイラ実行をやめる)438270
PHP 8.4でもJIT 有効化を試みる433228
PHP 8.3に戻してプロファイラ実行せずにベンチ回してみる431496
PHP 8.3に戻してプロファイラを再び実行する344578
PDO::ATTR_PERSISTENT を設定する
371402
composer autoloader optimize 設定する
370456
Unix domain socket を使うようにする377267
各種パラメータ調整、PHP8.4に戻す、ログを無効化
533117
MySQL 8.0 → 8.4 へアップグレード502465
MySQL 8.4 → 9.1 へアップグレード498680
感想
素振りを進める中で思ったこととしては、結局プログラミング言語 として何を選んだとしても大きな影響はなさそうということです。昨今ISUCONにGo言語で挑戦する人が多いですが(私含め)、ボトルネック はデータベースやアプリケーションロジックがメインなので、手に馴染んだ言語で挑戦するのが良さそうだなと改めて気付かされました。
与えられた時間が無制限にある場合Go言語は最終的にテンプレートの生成がボトルネック になっていくのをprivate-isuに前回挑んだ時に感じましたが、PHP の場合はPDOのコンストラク タを作るところに行き着く(なのでPHP -FPMをやめよう)という部分に言語特有の違いが感じられて面白かったです。ただ、ISUCON当日にここまでたどり着く時間的余裕はなかなかなさそうなのでそんなに「PHP -FPMからの移行の素振り」とかは気にしなくてもいいかもと思ったりしました。
アプリケーションの負荷やエラーログの確認方法はエンバグ したときのデバッグ に不可欠な要素なので、その点だけしっかりと見直しておけると良いと思います。